Introduction
This project was entered into as a learning experience, to enhance my knowledge of machine learning, as well as TensorFlow specifically. At the end, I wanted to have a trained machine learning model that runs in the browser to reliably (at least 80% accuracy, >90% preferred) solve the 4Chan CAPTCHA. These goals were achieved - let's talk about how I got there!
If you'd like to follow along with the code references, I have made the code public on GitHub here.
Terminology
- CAPTCHA: A challenge-response test to determine whether or not a computer or website user is a human. The acronym stands for Completely Automated Public Turing test to tell Computers and Humans Apart.
- 4Chan: A public, anonymous imageboard website with discussion boards on various topics. These boards are used for posting images and text discussions. Filling out a CAPTCHA is required before every post or reply.
- Normal CAPTCHA: The simplest form of the 4Chan CAPTCHA, that consists of an image with 5 or 6 alphanumeric characters. The user must read and correctly enter all of the characters in a field in order to make a post on 4Chan.
- Slider CAPTCHA: A more complex form of the 4Chan CAPTCHA, that consists of a background image with random-looking character fragments, and a foreground image with transparent "holes" or "windows" in it. A slider in the browser CAPTCHA form must be moved to correctly align the two images in order to see the CAPTCHA text.
Getting the Data
I've heard many times that the hardest part of any machine learning problem is getting the data to train your model. This assertion was definitely pertinent here, for several reasons. There's two parts to this problem: Getting the CAPTCHAs, and getting solutions to those CAPTCHAs.
Scraping CAPTCHAs from 4Chan
After looking at the HTTP requests in the browser console when requesting a new CAPTCHA, I found that it makes a request to https://sys.4chan.org/captcha?framed=1&board={board}, where {board} is the name of the board we're trying to post on. The response is an HTML document that contains a script tag with a window.parent.postMessage() call with some JSON. On a hunch, I tried to remove the framed=1 parameter, and found that this causes it to just spit out the raw JSON. That should be easier to work with. The JSON looks like this:
{
"challenge": "[some long and random string here]",
"ttl": 120,
"cd": 5,
"img": "[a base64 string here]",
"img_width": 300,
"img_height": 80,
"bg": "[a base64 string here]",
"bg_width": 349
}
Some of these keys are pretty obvious. ttl and cd are the least obvious to me. I know from experience that the 4Chan CAPTCHA only displays for about 2 minutes before it expires and you have to request a new one, so that's what ttl must be. But what about cd? Let's make another request, shortly after the first one:
{
"error": "You have to wait a while before doing this again",
"cd": 23
}
If I keep making the same request, the cd parameter steadily decreases, at a rate of about 1 per second. Alright, so this is how long you have to wait before requesting a new CAPTCHA. cd likely stands for "cooldown".
If I wait the 23 seconds, and then make another request, I get a successful response, but this time, the cd is 32. We have to wait longer every time. After some experimentation with a script, it looks like the first few requests can be made every 5 seconds, then it increments to 8, and then continues to roughly double until it's capped at 280 seconds, and stays there.
Additionally, once you've hit the 280 second timers, the CAPTCHA gets somewhat harder. It looks like this:

instead of this:

So, there's some throttling in place. The data also gets of lower (but still usable) quality if you make too many requests.
Something I will briefly touch on is that the user has to pass a Cloudflare Turnstile challenge to even request a CAPTCHA in the first place. As a result, simply using many proxies with a naive script is not realistic, without first passing the Cloudflare Turnstile and saving the relevant cookies. When I was scraping CAPTCHAs with the script I wrote for this, I simply copied the Cloudflare cookies from my browser, and manually replaced them whenever they expired.
I scraped several hundred CAPTCHAs in this manner - not enough to train the model, but it's at least a start. This still leaves us with a problem, though. We have all these CAPTCHAs, but we don't have the solutions. I could fill them out manually, but instead, let's try something else.
Getting the Solutions
Or, Humans are bad at solving the 4Chan CAPTCHA.
A recurring theme in this project has been "this is easy for a computer to do, but hard for a human to do." Many users find the "slider" style CAPTCHAs incredibly frustrating, but I've had a 100% success rate in aligning them with the heuristic script I made (trainer/captcha_aligner.py). The 4Chan CAPTCHAs in general are widely considered by users of the site to be frustrating to solve. But, surely, for people who solve CAPTCHAs for a living, it shouldn't be an insurmountable challenge, right?
I coded a quick script (seen in the project under trainer/labeler.py) to send the CAPTCHAs to a commercial CAPTCHA solving service, where real humans would solve the CAPTCHAs for me for a nominal fee. Writing the script was simple, but actually employing it was an exercise in frustration. I sent a couple dozen CAPTCHAs to the service, and nearly all of them came back with one or more characters incorrectly solved.
The service has a feature called "100% Recognition", which allowed me to specify that all my requests be first sent to n workers, and if x of those workers don't return the same solution, then send them to up to y more workers. It would only return an error after sending the CAPTCHAs to n + y workers and not getting at least x solutions the same. I configured my account with the values n = 2, x = 2, and y = 3 - that is, initially send the CAPTCHA to 2 workers, and if they don't both agree, then send them to up to 3 additional workers until two of them agree, or none of them agree.
This improved the situation somewhat. About 80% of the CAPTCHAs were now being successfully solved, and after reviewing the results, 90% of those were correct, but about 10% had errors in them, which indicated that multiple workers were making the same mistakes. This was still less than ideal.
A quick aside: What if I just ask someone I know to be reliable to do it for me, or even do it myself? I explored both of these approaches. I wrote a quick user script that saved the CAPTCHA image and the solution text, and just sat there requesting and solving CAPTCHAs in my free time. I also asked a good friend of mine to do the same. This yielded several hundred images, which I did add to the training set, but in the end this approach was abandoned because we still ran into the throttling problem, and the problem of the CAPTCHAs getting harder (and eventually, near-impossible) if you request too many of them.
I begun to wonder if there was a different way to look at this altogether. What if we didn't need to scrape CAPTCHAs and have them solved by humans?
Generating Synthetic Data
What if we could generate our own 4Chan CAPTCHAs? 4Chan, and the CAPTCHA it uses, are not open source, so I couldn't literally run the same code locally. But I could definitely approximate it.
The 4Chan CAPTCHA can be dissected into two main parts. The background, which looks like this:
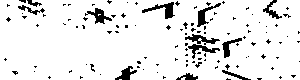
and the characters, which look like this:
We don't need to generate our own backgrounds from scratch. It's a relatively simple computer vision problem to take an image like the 4Chan CAPTCHA, and find all of the large contours in the image, which represent the characters, and remove them. This leaves only the noisy background, as seen in the image above, which was generated using this algorithm.
Next, we need to isolate a decent number of characters, and label them with their values. If this was trivial to do with an algorithmic script, well, we wouldn't be here, because solving the CAPTCHA would also be trivial to do with an algorithmic script :) It's pretty easy to do this by hand, though, and that's what I settled on doing. It was annoying. I tagged the characters with VoTT and then extracted them with a quick and dirty script, which also postprocessed them to make sure it was only the characters in the images. I ended up with 50-150 isolated images of each character. It was during this stage of the project that I realized the 4Chan CAPTCHA includes only the characters 0, 2, 4, A, D, G, H, J, K, M, N, P, R, S, T, W, X, and Y - likely done to avoid ambiguity.
Now we just have to put it all together. When extracting the digits, I observed a few patterns in how the characters are usually clustered or spread apart, and so I wrote my script to assemble images with backgrounds according to these formulas. And, of course, since the input character images are labelled, I can easily label the generated synthetic CAPTCHAs with their solutions.
Creating the Model
Now we've got the data, it's time to train the model. I assembled a model architecture based on some research, after reading several different articles on CAPTCHA solving using neural networks. I settled on an LSTM CNN architecture with 3 convolutional/max-pooling layers and 2 LSTM layers. A fourth convolutional layer was also tested, but it did not improve performance. CTC encoding of the CAPTCHA text was used, because the output was of variable length (either 5 or 6 characters). I built the model using Keras on top of TensorFlow.
Processing the data
The input to the model was a mix of pre-aligned slider CAPTCHAs, normal CAPTCHAs, and synthetic CAPTCHAs. The training script took care of ensuring they were 300x80 pixels and converted to pure black-and-white.
Always read the docs
The arguments might not be in the order you expect.
One of the important steps in my data processing pipeline was making sure that all the CAPTCHA images are exactly 300x80 pixels. Some images from the dataset, namely the older aligned "slider" CAPTCHAs, don't match this resolution / aspect ratio. I could just fix the training data, but it's better in the end to make the training script able to cope with any data I throw at it.
I used tf.image.resize() for this. The docs on this are pretty simple,
for my use case I just need to pass the input image tensor, and the size, which is probably just a tuple of (width, height), right?
Well, I made that assumption, and the code ran fine, so I didn't really give it a second thought.
Until... My model's performance was absolutely abysmal! Even after training for 32+ epochs, the model barely performed at all on images it had seen before, and it really couldn't make anything at all of brand new CAPTCHA images, yielding seemingly random predictions. What the heck was going on?
I decided to actually visualize the images I was feeding into the model, and see what they looked like - maybe my black/white thresholding was going wrong? I took a random image from the input data after processing, and visualized it, and I got... this:
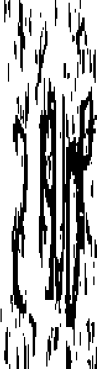
Yeah, you probably saw that coming as soon as I said "probably just a tuple of (width, height)". Turns out it's not. It is, in fact, a tuple of (height, width)! Had I taken the time to read the whole documentation page, I would have found this near the bottom of the page, where it provides more detail on the expected argument. This is definitely a lesson learned - read the documentation thoroughly when working with libraries you're unfamiliar with, even if you think you know how it works, and especially if things aren't working how you'd expect.
After fixing this bug, the training performance looked a lot more promising.
Training the model
The final dataset consisted of approximately 500 hand-solved images, and approximately 50,000 synthetically-generated images. The synthetic images were generated based on random samples from approximately 2,500 background images and 50-150 images of each character. This dataset was randomly shuffled, and then segmented 90/10 into training and evaluation sets. Training took approximately 45 seconds per epoch on my NVIDIA RTX A4000 Laptop GPU.
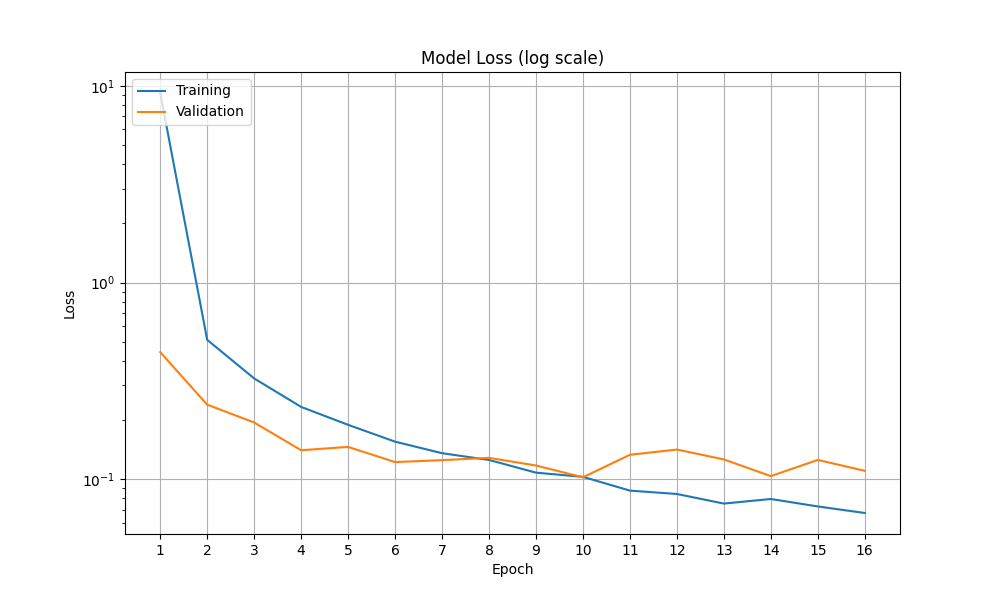
At the end of the first epoch, the loss did not look very promising - it's still all the way up at 19. During the evaluation callback phase, predictions were nowhere near correct, yielding only 1-2 predicted characters that didn't match any of the characters in the image. This is to be expected during the early stages of training.
Later epochs greatly improved performance. By the end of the fourth epoch, loss decreased to 0.55, and the predictions were already looking good, with 5/5 of the random test predictions at this stage yielding correct results. Loss steadily decreased throughout the rest of the training epochs.
After experimenting with different numbers of epochs, 8-16 epochs was found to be a good trade-off between time and final model performance. Loss stabilized by the 8th epoch, and increasing the epoch count beyond 16 yielded greatly diminishing returns.
I wrote a quick test script (trainer/infer.py) to infer CAPTCHA solutions in Python. Results were promising on images the model had not seen before, yielding correct solutions in the limited number of test cases I tried.
Using the Model in TensorFlow.js
Writing the TensorFlow.js code for the user script was quite straightforward. I chose TypeScript for this task. I re-implemented the CAPTCHA alignment algorithm from the Python code, as well as the image preprocessing code. All of this code is located in the user-scripts/ directory in the repository.
The Python TensorFlow/Keras model formats aren't compatible with the model format expected by TensorFlow.js. There's an official conversion script, with instructions on how to use it. This should be easy, right?
The converter doesn't work on Python 3.12
This was a pretty simple problem that took awhile to figure out. The official TensorFlow-to-TFJS model converter doesn't work on Python 3.12. This doesn't seem to really be documented, and the error messages thrown when you try to use it on Python 3.12 are non-obvious. I tried an older version of Python (3.10) on a hunch, using PyEnv, and it worked like a charm.
TensorFlow.js doesn't support Keras 3
New problem: The conversion script supports converting Keras 3 models to TensorFlow.js format. The only problem? TensorFlow.js doesn't support actually reading those converted models. I found this out from a forum post, after I spent a bit of time puzzling out why TFJS wouldn't read the model that the official conversion script output.
Luckily, the solution was easy: Use Keras 2. We can do this by training the model with the environment variable TF_USE_LEGACY_KERAS=1 set, after installing the legacy tf_keras package. This may require some code changes. In my case, I only had to trivially modify one line. We also have to export the model using the legacy .h5 model format, and specify that as the input format when running the conversion script.
Real-World Performance
We've seen the performance on the training dataset, which consists mainly of synthetic images. But it doesn't matter if it can solve synthetic CAPTCHAs - we care about solving the real ones.
Good news: It works great on the real 4Chan CAPTCHA. Solving is fast, taking about 1 second to load the model the first time, and then being imperceptibly quick on subsequent executions. In my experience over hundreds of real CAPTCHAs solved in the browser, the model exhibits a greater than 90% successful solve rate. It rarely gets characters wrong - when it is innacurate, it typically omits a single character entirely. I believe this could be improved with greater training on actual data, or possibly tweaking the CAPTCHA layouts in the synthetic dataset generator.
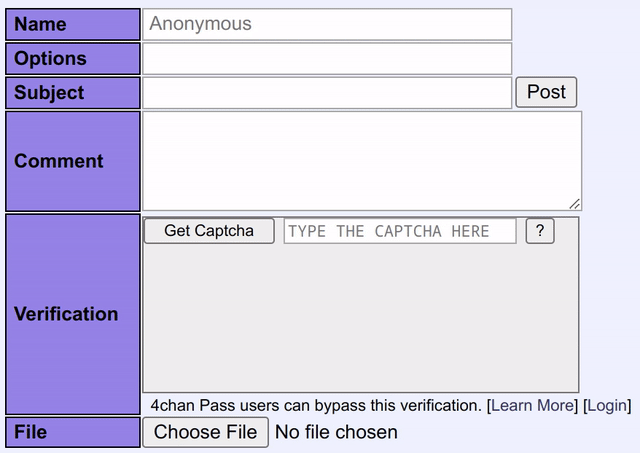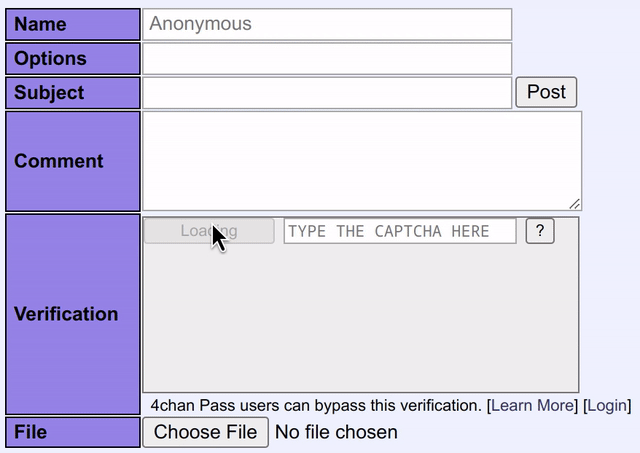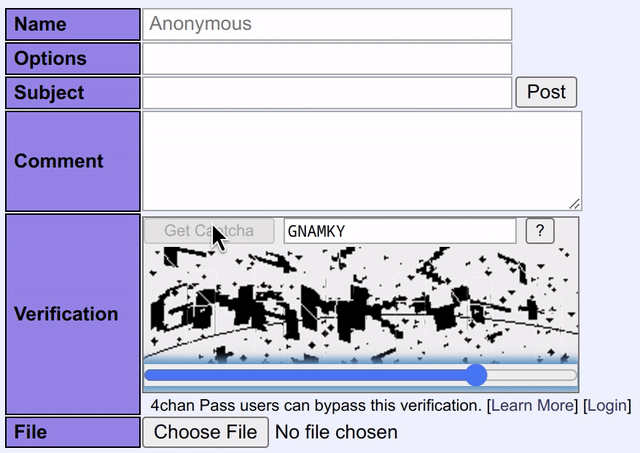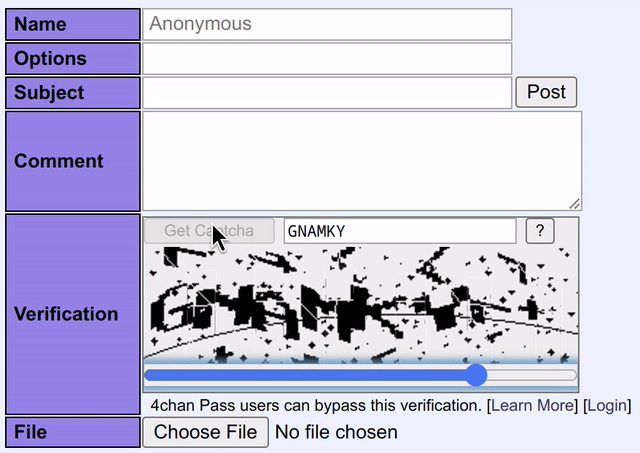
Small fun fact: This model has far better accuracy than the human-powered CAPTCHA solving service I described above.
4-character CAPTCHAs
While I was writing and editing this article after completing the project, I noticed that 4Chan begun sometimes serving CAPTCHAs with only 4 characters, rather than the usual 5 and 6-character CAPTCHAs. Despite this model only having been trained on 5 and 6-character CAPTCHAs, performance on the 4-character CAPTCHAs is the same as for the 5 and 6-character CAPTCHAs.
Conclusion
I enjoyed this project a lot. It had a few challenges to overcome, and I learned a ton about machine learning and computer vision in the process. There are surely improvements that can be made, but for now, I'm pleased with the results, because I achieved what I set out to do from the start.
I hope you enjoyed reading this write-up as much as I enjoyed writing it, and I hope you learned something too!
